C++/C# programmer
Developed in November 2022

Showcase of the main character's voice
In my internship, I worked on a serious game meant to help people with acquired brain damage learn coping strategies to deal with their new disabilities.
The game contains a lot of text and the target audience often gets tired rather quickly, so it made sense to add Text-to-Speech to make the game more accessible.
I chose to use the Azure Speech Service to generate the audio. This is mainly because of its C++ SDK, which makes it easily accessible in a highly performant environment. This was important because there would be a lot of processing to be done on the gained data. It also has a great demo page, where the client can easily test multiple voice settings, smoothening our collaboration.
Azure’s Speech service has a great REST API for long pieces of audio that provides a .zip file of audio files per paragraph. I wrote a full implementation of the tool using this API using libcurl in C++.
However, the long audio API isn’t free, and the default API is free for up to 0.5 million characters per month. Our project only had ~180.000 characters, meaning there could be several full rewrites within that range. It just made more sense to use this API and apply some processing to the result.
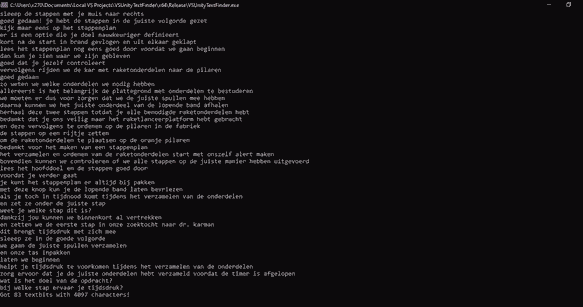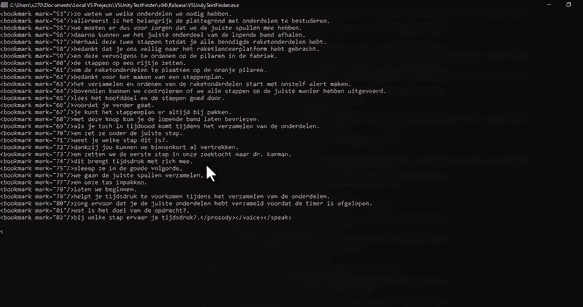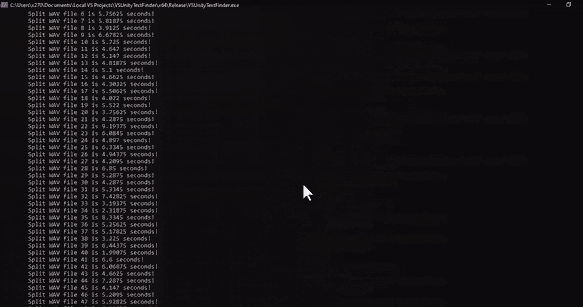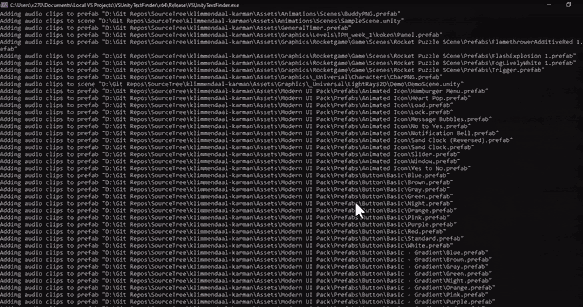
Generation of text bits into SSML batches and then cutting the resulting files
With the C++ SDK, you can generate shorter pieces of audio (maximum of 10 minutes). The voice data is entered with SSML markup. This markup does count as billable characters, and since every bit of text will need to have voice settings, this can cause some major overhead.
To limit this, I decided to batch many text bits together and then split the result into multiple audio files. To simplify this process, I chose to request the uncompressed .wav file format for the generated audio. Then, I could simply calculate what parts of the data buffer to copy into separate files with similar header data.
This cut down the markup overhead from being included in every text bit (about 2000 times), to every batch (maximum of 27 times).
To know where to cut the audio, I first used the bookmark elements provided by SSML. This seemed to work at first, but I found that they become less reliable as audio files grow longer. They would be so inaccurate at times that I had to come up with a new solution. I decided to simply detect sentence breaks by finding long pieces of empty audio data. Then, I detected how many sentences each text bit had by parsing its punctuation.
Later, when I added support for multiple voices, this audio-cutting system broke because the breaks between sentences were different for every voice. My solution was to add three-second break elements after every text bit to the markup. This was longer than any break between sentences for any voice, meaning I could accurately detect where text bits begin and end without parsing punctuation. This is a far more robust solution.
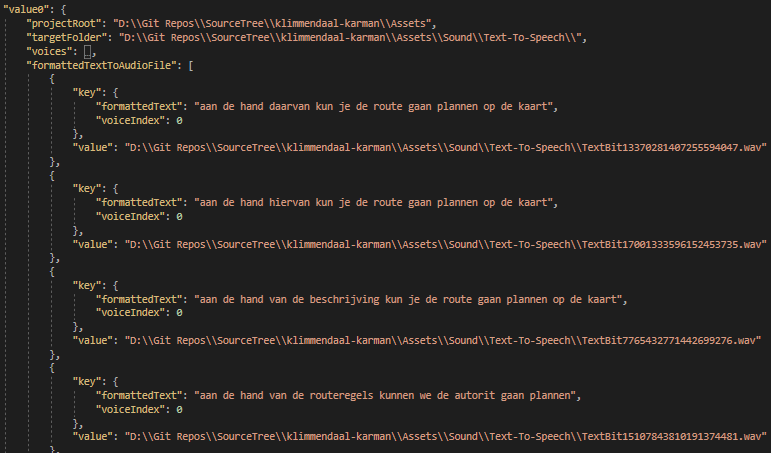
Screenshot of the save file containing a map from formatted text bit to audio file
It doesn’t make much sense to generate the same audio files more than once, so I used the cereal library to generate a JSON file that tracked what formatted text corresponds to what audio file. This way, whenever the tool is run, I can choose to only generate audio that doesn’t exist yet.
It also doesn’t make much sense to keep audio files around if you don’t use them anymore. So I also added a step where the tool checks for text bits that don’t appear in the game anymore and made it delete those files.
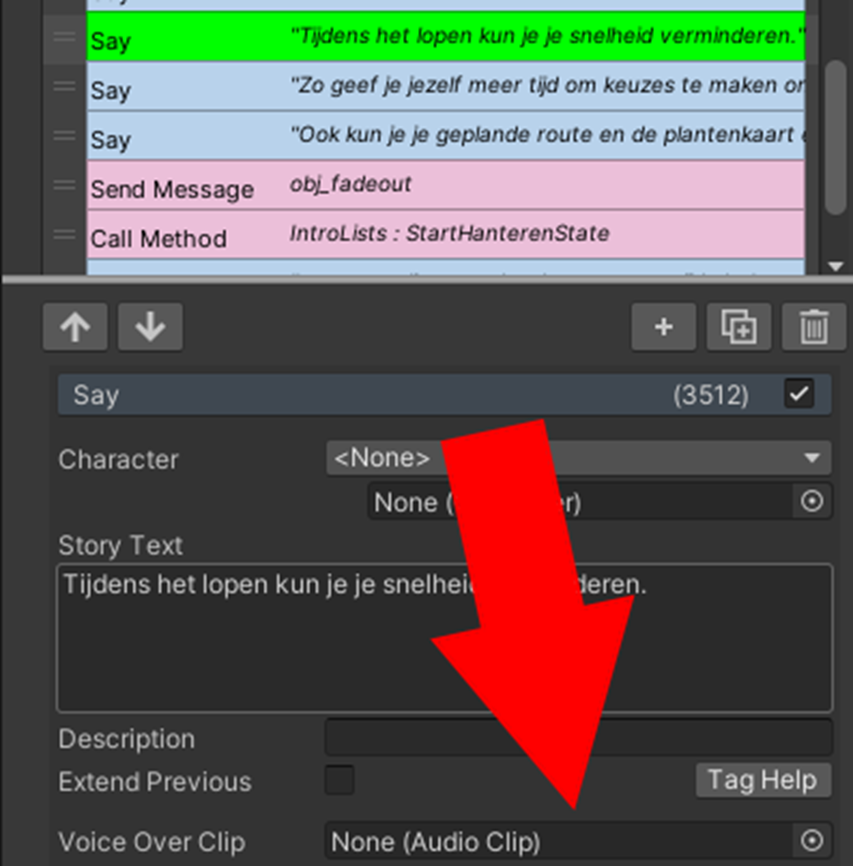
Audio files could simply be placed into the Voice Over Clip parameter within Fungus
Integrating this tool into the project was quite simple. The project is made in Unity and it uses the Fungus plugin to manage its text. There isn’t anything like a text database here, so I had to parse the text from the scene files.
The text is saved in Fungus “say” commands, which also have a parameter for a voice line. This was perfect since that will automatically make it play and stop playing whenever text is shown. All I had to do was place the right audio files into the right commands.
The commands used for text are saved as monobehavior components. Their serialized parameters can be easily accessed within the YAML-formatted scenes and prefabs. All I needed to do was extract the text from the “storyText” parameter, generate the audio files, and then reference the resulting file in the “voiceOverClip" parameter.
The audio files are referenced with their GUID, which is an ID that unity gives to asset files. for GUIDs to exist, Unity needs to first import the asset to generate a .meta file that contains it. At first, I tried to implement this by calling Unity from the command-line, but this was too complex for this project. It was easier to simply ask the user to open the Unity project and track the number of .meta files until they have all been generated.
Some text was stored in Fungus commands that were contained in prefabs. This complicated things a little bit, since I now had to also detect overrides of the text parameter in scenes. Then, I had to add an additional override for the audio.
Showcase of two characters talking to each other
The project has multiple characters, meaning there should also be support for multiple voices.
To do this, I had to find a way to choose what text uses what voice. I decided to simply add a parameter to the Fungus “say” commands that had an enum value for the voice. I placed the voice data of every index into a separate JSON file. This makes it easy for everyone working on the project to choose voices.
In the tool, I had to do a little bit more work. Before, the text bits were sorted and differentiated by only the text. This had to include the voice index now as well.
I also had to take this into account when generating the SSML markup. An optimization for this could be to sort by voice first and by text second, to minimize the number of times a voice is changed and thus the number of billable characters.
Project tags: #Applied Game, #C++, #Existing Codebase, #Healthcare, #Multidisciplinary, #REST API, #Tools, #Unity